ファインチューニング
本章では、ディープラーニングで多く用いられるファインチューニング (fine tuning) について学んでいきます。ファインチューニングとは、異なるデータセットで学習済みのモデルに関して一部を再利用して、新しいモデルを構築する手法です。モデルの構造とパラメータを活用し、特徴抽出器としての機能を果たします。手持ちのデータセットのサンプル数が少ないがために精度があまり出ない場合でも、ファインチューニングを使用すれば、性能が向上する場合があります。
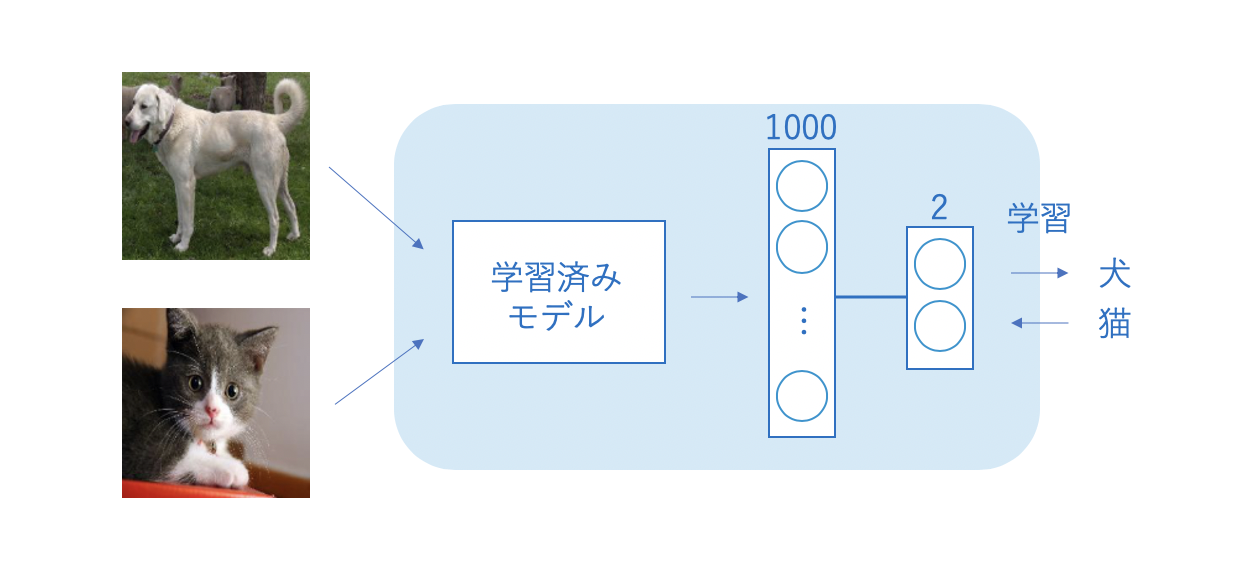
類似した用語として転移学習 (transfer learning) がありますが、学習済みモデルをそのまま使用するか、一部を使用するかで異なります。現時点では、似ているけど少し違う言葉、という認識で大丈夫です。

本章の流れは、
- データを準備して理解する
- 自作した分類モデルで学習と評価
- 事前学習済みモデルの重みを読み込んで学習と評価
上記のように、一度自作のモデルを組んで結果を確認した後に、ファインチューニングをすればどの程度精度が向上するかを見ていきます。
本章の構成
- 画像分類 (CIFAR10)
- 学習済みモデルの活用
画像分類 (CIFAR10)
前章で扱った手書き文字である MNIST の分類は簡単なモデルの定義でもある程度の正解率が得られますが、もう少し難しい問題設定で試してみましょう。CIFAR10 と呼ばれる以下のような 10 クラスの分類を行います。CIFAR10 は MNIST のグレースケール画像とは異なり、フルカラー画像です。CIFAR10 も MNIST と同様に、torchvision にデータセットが用意されています。

データセットの準備
torchvision を使ったデータのダウンロード方法からデータセットの分割方法は前章と同じ流れです。
# 最初にインストール
!pip install pytorch-lightning
import torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
import pytorch_lightning as pl
from pytorch_lightning import Trainer
transform = transforms.Compose([
transforms.ToTensor()
])
# CIFAR10
train_val = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transform)
test = torchvision.datasets.CIFAR10(root='data', train=False, download=True, transform=transform)
# train : val = 8 : 2
n_train = int(len(train_val) * 0.8)
n_val = len(train_val) - n_train
# ランダムに分割を行うため、シードを固定して再現性を確保
torch.manual_seed(0)
# train と val を分割
train, val = torch.utils.data.random_split(train_val, [n_train, n_val])
len(train), len(val), len(test)
モデルの定義と学習
今回はチャネルの数を 3 => 64 => 128 => 256 のように増やしていきながら、畳み込みのたびにハーフサイズのプーリングを行います。これは VGG16 という有名なモデル構造を参考に、さらに簡略化したモデル構造を採用しています。学習や検証の流れは同じであるため、MNIST で定義した TrainNet, ValidationNet, TestNet を使用します。モデルで使用する層の宣言と順伝播の流れだけ変更します。
class TrainNet(pl.LightningModule):
@pl.data_loader
def train_dataloader(self):
return torch.utils.data.DataLoader(train, self.batch_size, shuffle=True)
def training_step(self, batch, batch_nb):
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
results = {'loss': loss}
return results
class ValidationNet(pl.LightningModule):
@pl.data_loader
def val_dataloader(self):
return torch.utils.data.DataLoader(val, self.batch_size)
def validation_step(self, batch, batch_nb):
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
results = {'val_loss': loss, 'val_acc': acc}
return results
def validation_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
avg_acc = torch.stack([x['val_acc'] for x in outputs]).mean()
results = {'val_loss': avg_loss, 'val_acc': avg_acc}
return results
class TestNet(pl.LightningModule):
@pl.data_loader
def test_dataloader(self):
return torch.utils.data.DataLoader(test, self.batch_size)
def test_step(self, batch, batch_nb):
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
results = {'test_loss': loss, 'test_acc': acc}
return results
def test_end(self, outputs):
avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean()
avg_acc = torch.stack([x['test_acc'] for x in outputs]).mean()
results = {'test_loss': avg_loss, 'test_acc': avg_acc}
return results
class Net(TrainNet, ValidationNet, TestNet):
def __init__(self, batch_size=256):
super(Net, self).__init__()
self.batch_size = batch_size
# 使用する層の宣言
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = nn.Conv2d(64, 128, 3, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.Conv2d(128, 256, 3, padding=1)
self.bn3 = nn.BatchNorm2d(256)
self.conv4 = nn.Conv2d(256, 512, 3, padding=1)
self.bn4 = nn.BatchNorm2d(512)
self.fc = nn.Linear(2048, 10)
def lossfun(self, y, t):
return F.cross_entropy(y, t)
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=0.01)
def forward(self, x):
# ch: 3 -> 64, size: 32 * 32 -> 16 * 16
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2, 2)
# ch: 64 -> 128, size: 16 * 16 -> 8 * 8
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2, 2)
# ch: 128 -> 256, size: 8 * 8 -> 4 * 4
x = self.conv3(x)
x = self.bn3(x)
x = F.relu(x)
x = F.max_pool2d(x, 2, 2)
# ch: 256 -> 512, size: 4 * 4 -> 2 * 2
x = self.conv4(x)
x = self.bn4(x)
x = F.relu(x)
x = F.max_pool2d(x, 2, 2)
# 512 * 2 * 2 = 2048
x = x.view(-1, 2048)
x = self.fc(x)
return x
# 再現性の確保
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(0)
# モデル学習の準備
net = Net()
# 単一の GPU で学習
trainer = Trainer(gpus=1)
# モデルの学習
trainer.fit(net)
# 検証データ&テストデータに対する結果
trainer.test()
trainer.callback_metrics
この結果から、10 クラスの分類であるため、ベースラインとなる正解率が 10% (=1/10) とすると、正解率を約 54 % 程度までは上昇させることができていますが、それでもまだ正解率は高いとは言えない結果になっています。
学習済みモデルの活用
冒頭で説明した通り、ファインチューニングをおこないます。学習済みモデルは世界中で公開されており、それぞれのタスクに合わせて学習済みモデルを使用する必要があります。
今回は、世界最大の画像認識コンペティション ImageNet Large Scale Visual Recognition Competition (ILSVRC) で使用されている 1000 クラスの物体を分類するタスクの学習済みモデルを利用します。この ILSVRC の学習済みモデルはフレームワーク側で用意されていることが多く、簡単に使い始めることができます。まずは、この学習済みモデルで試してみると良いでしょう。また、モデルの構造は ResNet18 という ILSVRC にて 2015 年に優勝したものを使用します。今でも幅広く活用されているモデルです。
学習済みモデルは torchvision.models 以下に置かれています。今回使用するモデル以外にも画像分類モデルであれば、
- AlexNet
- VGG
- ResNet
- SqueezeNet
- DenseNet
- Inception v3
- GoogLeNet
- ShuffleNet v2
- MobileNet v2
- ResNeXt
- Wide ResNet
- MNASNet
があります。
# 学習済みモデル
from torchvision.models import resnet18
学習済みパラメータを使用する場合には、pretrained=True としてください。モデル構造のみを使用したい場合は False とすればランダムに重みが割り振られます。
# ResNet を特徴抽出器として使用
resnet = resnet18(pretrained=True)
また、学習済みモデルを利用するときには、学習時に使用していた画像サイズや正規化を合わせる必要があります。PyTorch の公式ページ に指定があり、まず画像のサイズは 224 x 224 となります。画像の変換は transform に定義しておきます。
transform = transforms.Compose([
# 画像サイズを 224 x 224 にサイズを変更
transforms.Resize((224, 224)),
# torch.Tensor 形式に変換
transforms.ToTensor(),
# 学習済みモデルで使用されていた平均と標準偏差を用いて標準化 (RGBの3チャネル)
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 前処理を追加したデータセットの読み込み
train = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transform)
学習用のデータを 1 つ使用して、推論までの計算を確認していきましょう。
# 入力値を抽出
x = train[0][0]
# サイズの確認
x.shape
# 先頭に batch_size を追加
x = x.unsqueeze(0)
x.shape
# 推論
y = resnet(x)
# サイズの確認
y.shape
この結果から分かるように、学習したタスクが 1000 クラスの分類であったため、1000 個の値が出力値として得られています。
モデルの学習
それでは、一連の流れが確認できたため、学習済みモデルを用いたファインチューニングを行います。ファインチューニング時には活用する学習済みモデルのパラメータは学習させずに固定します。モデルの構成が大きくなったこと、そして画像のサイズが大きくなったことにより、学習にかかる時間が大幅に増えます。そのため、今回は最大 10 エポックに制限しておきましょう。
# CIFAR10 のデータセットに定義した前処理を施す
train_val = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transform)
test = torchvision.datasets.CIFAR10(root='data', train=False, download=True, transform=transform)
# データセットの分割
torch.manual_seed(0)
n_train = int(len(train_val) * 0.8)
n_val = len(train_val) - n_train
train, val = torch.utils.data.random_split(train_val, [n_train, n_val])
class Net(TrainNet, ValidationNet, TestNet):
def __init__(self, batch_size=256):
super(Net, self).__init__()
self.batch_size = batch_size
# 使用する層の宣言
self.conv = resnet18(pretrained=True) # 学習済みモデルを利用
self.fc = nn.Linear(1000, 10)
# 学習済みのパラメータを固定
for param in self.conv.parameters():
param.requires_grad = False
def lossfun(self, y, t):
return F.cross_entropy(y, t)
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=0.01)
def forward(self, x):
x = self.conv(x)
x = self.fc(x)
return x
# 再現性の確保
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(0)
# 学習
net = Net()
trainer = Trainer(gpus=1, max_nb_epochs=10)
trainer.fit(net)
# 検証データ&テストデータに対する結果
trainer.test()
trainer.callback_metrics
上記の結果の通り、10 エポック分の学習にて正解率を 79% まで高めることができました。さらなる学習やハイパーパラメータの調整でさらに正解率を高められることが期待できます。


